GoogleNet
原文: https://arxiv.org/pdf/1409.4842
Inception
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block),Inception块由四条并行路径组成。 前三条路径使用窗口大小为1x1、3x3和的5x5卷积层,从不同空间大小中提取信息。 中间的两条路径在输入上执行1x1卷积,以减少通道数,从而降低模型的复杂性。 第四条路径使用3x3最大汇聚层,然后使用卷积层来改变通道数。 这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
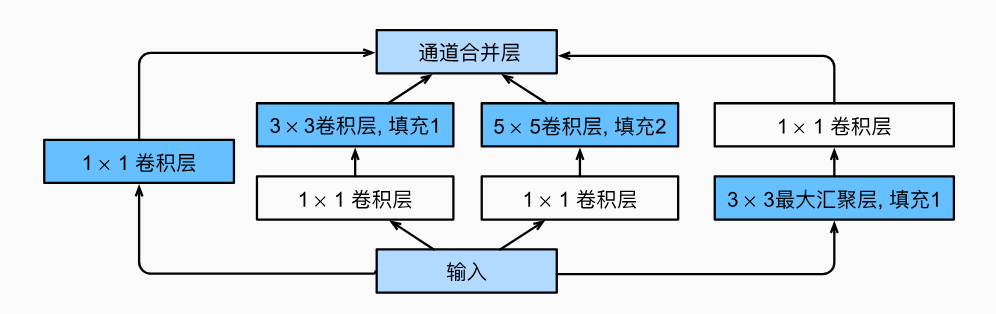
import torch
from torch import nn
from torch.nn import functional as F
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
那么为什么GoogLeNet这个网络如此有效呢? 首先我们考虑一下滤波器(filter)的组合,它们可以用各种滤波器尺寸探索图像,这意味着不同大小的滤波器可以有效地识别不同范围的图像细节。 同时,我们可以为不同的滤波器分配不同数量的参数。
GoogleNet
GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。
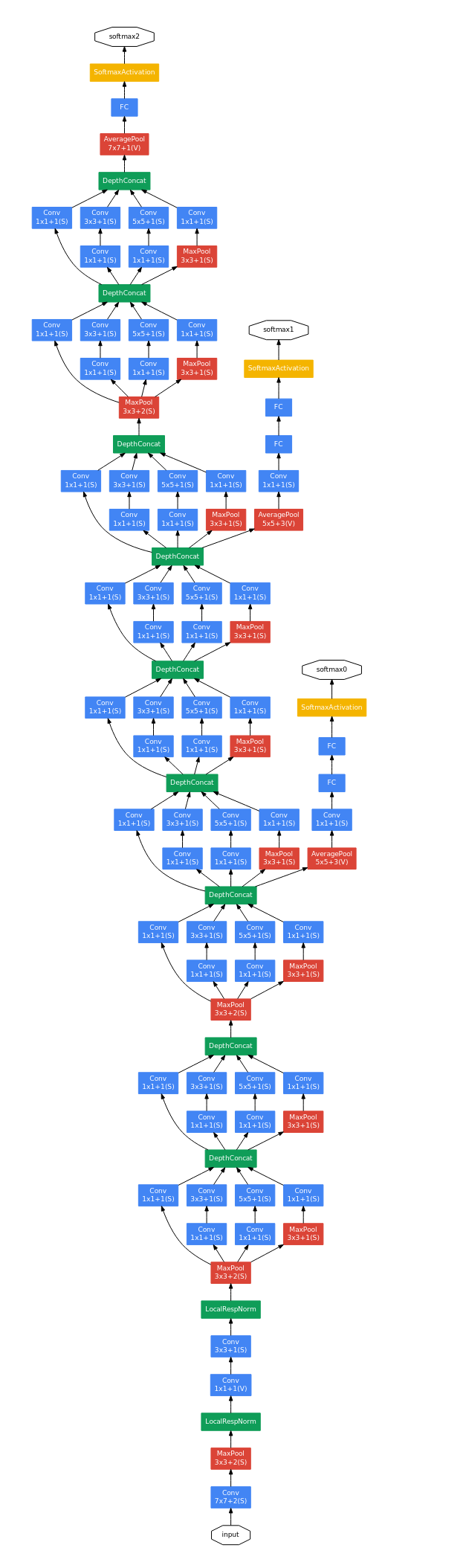
现在,我们逐一实现GoogLeNet的每个模块。第一个模块使用64个通道、7x7卷积层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第二个模块使用两个卷积层:第一个卷积层是64个通道、1x1卷积层;第二个卷积层使用将通道数量增加三倍的3x3卷积层。 这对应于Inception块中的第二条路径。
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第三个模块串联两个完整的Inception块。 第一个Inception块的输出通道数为64+128+32+32=256,四个路径之间的输出通道数量比为64:128:32:32=2:4:1:1。 第二个和第三个路径首先将输入通道的数量分别减少到96/192=1/2和16/192=1/12,然后连接第二个卷积层。第二个Inception块的输出通道数增加到128+192+96+64=480,四个路径之间的输出通道数量比为128:192:96:64=4:6:3:2。 第二条和第三条路径首先将输入通道的数量分别减少到128/256=1/2和32/256=1/8。
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第四模块更加复杂, 它串联了5个Inception块,其输出通道数分别是512、512、512, 528和832。 这些路径的通道数分配和第三模块中的类似,首先是含3x3卷积层的第二条路径输出最多通道,其次是仅含1x1卷积层的第一条路径,之后是含5x5卷积层的第三条路径和含3x3最大汇聚层的第四条路径。 其中第二、第三条路径都会先按比例减小通道数。 这些比例在各个Inception块中都略有不同。
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第五模块包含输出通道数为832和1024的两个Inception块。 其中每条路径通道数的分配思路和第三、第四模块中的一致,只是在具体数值上有所不同。 需要注意的是,第五模块的后面紧跟输出层,该模块同NiN一样使用全局平均汇聚层,将每个通道的高和宽变成1。 最后我们将输出变成二维数组,再接上一个输出个数为标签类别数的全连接层。
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
训练模型
import torch
from torch import nn
from torchvision import datasets, transforms
from torch.nn import functional as F
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from matplotlib_inline import backend_inline
from IPython import display
import time
def load_data_fashion_mnist(batch_size, resize=None):
"""Download the Fashion-MNIST dataset and then load it into memory.
Defined in :numref:`sec_utils`"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (torch.utils.data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=4),
torch.utils.data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=4))
class Accumulator:
"""For accumulating sums over `n` variables."""
def __init__(self, n):
"""Defined in :numref:`sec_utils`"""
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def accuracy(y_hat, y):
"""返回预测正确的样本个数(float 类型)"""
# 如果 y_hat 是 logits 或概率(如 [N, C]),取预测类别
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = torch.argmax(y_hat, dim=1)
# 比较预测 vs 真实标签,并确保类型一致(避免 int64 vs int32 问题)
cmp = (y_hat.to(y.dtype) == y)
# 求 cmp 中 True 的个数(True=1, False=0)
return float(cmp.sum()) # cmp.sum() 等价于 torch.sum(cmp)
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, nn.Module):
net.eval()
if not device:
device = next(iter(net.parameters())).device
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
class Animator:
def __init__(self, xlabel = None, ylabel = None, legend = None,
xlim = None, ylim = None, xscale = 'linear', yscale = 'linear',
fmts = ('-', 'm--', 'g-.', 'r:'), nrows = 1, ncols = 1,
figsize = (3.5, 2.5)):
if legend is None:
legend = []
backend_inline.set_matplotlib_formats('svg')
self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
self.config_axes = lambda: self.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def set_axes(self, axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):
axes.set_xlabel(xlabel)
axes.set_ylabel(ylabel)
axes.set_xlim(xlim)
axes.set_ylim(ylim)
axes.set_xscale(xscale)
axes.set_yscale(yscale)
if legend:
axes.legend(legend)
axes.grid()
def add(self, x, y):
if not hasattr(y, '__len__'):
y = [y]
n = len(y)
if not hasattr(x, '__len__'):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y , fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
def train(net, train_iter, test_iter, num_epochs, lr, device):
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timers = []
num_batches = len(train_iter)
for epoch in range(num_epochs):
metric = Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer = time.time()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], accuracy(y_hat, y), X.shape[0])
timers.append(time.time() - timer)
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / sum(timers):.1f} examples/sec '
f'on {str(device)}')
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=96)
train(net, train_iter, test_iter, num_epochs, lr, torch.device('cuda' if torch.cuda.is_available() else 'cpu'))
loss 0.251, train acc 0.904, test acc 0.892
2224.3 examples/sec on cuda
#