废话不多说,show you code.
我实现了两套内存池,一个是固定大小的内存池,一个是多重不同大小的内存池。
Fixed size memory pool
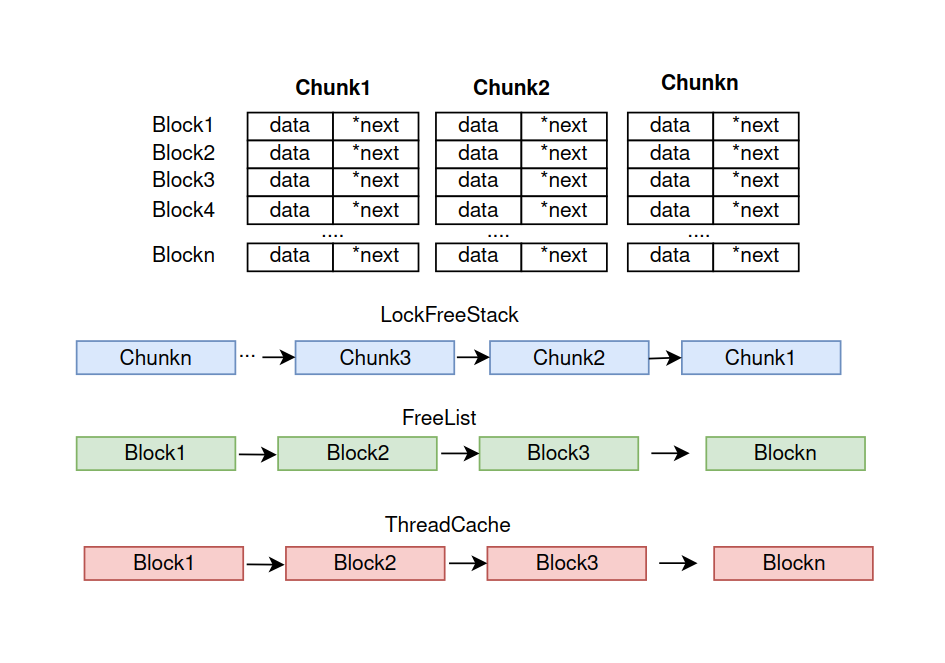
设计思路:
我们一个个看,首先我们定义了一个chunk, chunk 里面包含了n个block, 每个block都存放着一个data数据和一个next的指针,这个指针指向下一个block,形成一个链表。我们分配的时候是以一个个chunk来分配的,我们会把空闲的block 存放在freelist 里面。所以每次分配的时候都会先从freelist 中查看是否有空闲的block, 如果没有,再分配一个chunk。 但是呢,我们内存池考虑到thread-safe, 又要考虑到性能,所以使用了无锁操作,也就是原子操作(atomic)。 但是实际下来还是性能比较差,所以进一步优化使用threadcache, 也就是每个thread_local。这样就保证了每个thread都有自己的一份cache, 每次先分配的内存的时候就先从cache 分配,分配完再从freelist 中取。最后我们会把每个chunk数据push到LockFreeStack 里面管理,避免数据泄露。
LockFreeStack
无锁栈代码比较简单:
- 我们首先定义链表的节点Node,这个类是个模板类型的template
, T就是数据的格式,next是指向下个节点的指针。Node的构造函数声明了一个可变参数模板,允许接受任意数量和类型的参数,并使用std::forward 完美转发到data成员的构造函数。
struct Node {
T data;
std::atomic<Node*> next;
template<typename... Args>
Node(Args&&... args): data(std::forward<Args>(args)...), next(nullptr) {}
};
std::atomic<Node*> head;
-
push 操作:
- 使用
std::move(item)将传入的item值移动到新节点,避免不必要的复制, 并且利用了Node类中的完美转发构造函数 - 使用
std::memory_order_relaxed原子加载当前的头节点, 目前没有同步需求。 - 使用头插法把新节点插入到当前节点的前一个,这里循环条件使用CAS(Compare-And-Swap)操作尝试更新头节点
compare_exchange_weak会比较head与oldNode是否相等- 如果相等,则将
head设为newNode并返回true,循环结束 - 如果不相等(可能其他线程修改了
head),则将oldNode更新为当前的head值并返回false,循环继续
void push(T item) { auto* newNode = new Node(std::move(item)); Node* oldNode = head.load(std::memory_order_relaxed); do{ newNode->next.store(oldNode, std::memory_order_relaxed); } while(!head.compare_exchange_weak(oldNode, newNode, std::memory_order_release, std::memory_order_relaxed)); } - 使用
-
pop操作:
- 读取当前栈顶节点指针,使用宽松内存序
- 如果头节点为
nullptr,表示栈为空,返回false - 否则:使用CAS操作原子地更新头节点:
- 比较当前头节点是否仍为
oldNode - 若相同,将头节点更新为
oldNode->next并返回true - 若不同(其他线程已修改头节点),则更新
oldNode为当前头节点值并返回false
- 比较当前头节点是否仍为
- 成功更新头节点后,将原头节点的数据移动到结果变量
- 释放原头节点内存
- 返回操作成功
bool pop(T& result) { Node* oldNode = head.load(std::memory_order_relaxed); if (oldNode) { if (head.compare_exchange_weak(oldNode, oldNode->next.load(std::memory_order_relaxed), std::memory_order_release, std::memory_order_relaxed)) { result = std::move(oldNode->data); delete oldNode; return true; } } return false; }这里我们为什么使用
compare_exchange_weak而不是compare_exchange_strong呢?compare_exchange_weak允许在某些平台上”假失败”(spurious failure),即使比较的值实际相等,但在实现上可能会返回失败。这种设计让它能够:- 在某些CPU架构上有更高的性能
- 避免昂贵的内存栅栏(memory barrier)操作
- 特别在ARM等架构上实现更高效
- compare_exchange_strong: 保证只在实际值不等于期望值时返回失败, 如果失败需要重试,性能开销比较大。
- compare_exchange_weak: 可能出现假失败,但在循环中使用时,这种差异不影响结果正确性
LockFreeFixedSizePool
无锁的固定大小内存池。
-
首先看下我们的block的定义,这个结构体包含三个主要部分:
alignas(T)指令:确保Block结构体与T类型有相同的对齐要求,防止潜在的内存对齐问题data数组:- 类型:
std::byte数组,大小为sizeof(T) - 作用:存储T类型对象的原始内存
- 布局:位于Block结构体起始位置
- 类型:
next指针:- 类型:
std::atomic<Block*> - 作用:指向链表中的下一个Block,用于构建无锁链表
- 初始值:nullptr
- 类型:
as_object()方法:- 功能:将
data数组转换为T类型指针 - 实现:使用
reinterpret_cast进行类型转换 - 返回:指向
data内存区域的T*指针
- 功能:将
- 当对象被释放时,Block不会被系统回收,而是返回到池中供后续使用。每个Block作为无锁链表的节点,通过
next原子指针链接。 将data数组放在结构体起始位置,使得T对象指针可直接转换为Block指针。 当用户从内存池获取内存时,用户拿到的是指向data数组的T*指针。因为data位于Block结构体的起始位置,并且通过alignas(T)保证了对齐要求,所以可以安全地在deallocate时,将用户的T*指针转回Block*指针。
struct alignas(T) Block { std::byte data[sizeof(T)]; // 每个block的大小为T std::atomic<Block*> next{nullptr}; T* as_object() { return reinterpret_cast<T*>(data);} }; -
chunk的结构体有两个成员:
blocks: 一个指向Block数组的智能指针,使用std::unique_ptr<Block[]>管理内存count: 表示这个Chunk中包含的Block数量.Chunk实现了批量内存分配策略:- 一次性分配多个
Block对象 - 默认情况下,
N = 4096,单个Block大小为sizeof(Block) - 实际分配的
Block数量由BLOCK_PER_CHUNK = N / sizeof(Block)决定
- 一次性分配多个
std::unique_ptr<Block[]>为Chunk提供了自动内存管理:- 当
Chunk被销毁时,blocks指向的内存会被自动释放 - 避免了手动内存管理的复杂性和潜在的内存泄漏
- 当
- 构造函数接收一个
block_count参数,并完成两个操作:- 分配指定数量的
Block对象:std::make_unique<Block[]>(block_count) - 存储块数量:
count(block_count)
- 分配指定数量的
struct Chunk { // 每个chunk包含N个block std::unique_ptr<Block[]> blocks; size_t count; Chunk(size_t block_count) :blocks(std::make_unique<Block[]>(block_count)), count(block_count) {} }; -
再看下我们的ThreadCache的结构体的实现。ThreadCache是一个线程局部内的缓存系统,用于优化无锁内存池的性能。它主要为每个线程提供本地内存缓存,减少全局竞争,提高分配效率。
- 这里为什么把缓存的block块设置为32, 并且每次取的大小设置为16。
- 减少竞争:每次获取多个块,减少对全局空闲列表的访问频率。
- 适中开销: 16个块是内存和性能的平衡点,既不会一次占用过多内存,又能有效减少同步操作
- 批量效率:填充缓存时批量获取更高效,如在后面的
fill_local_cache()中使用。
- 这里我们为什么需要一个
pool_instance的指针。因为我们在内存归还给全局freelist, 所以这里我们传递一个指向对象的指针。
struct ThreadCache { Block* blocks[32]; int count = 0; static constexpr size_t BATCH_SIZE = 16; // 批量获取块的数量 LockFreeFixedSizePool<T, N>* pool_instance = nullptr; ~ThreadCache() { if (count > 0 && pool_instance) { return_thread_cache(); } } // 将线程本地缓存归还全局链表 void return_thread_cache() { if (count == 0 || !pool_instance) return; //将本地缓存链接成链表 for (int i = 0; i < count - 1; ++i) { blocks[i]->next.store(blocks[i+1], std::memory_order_relaxed); } Block* old_head = pool_instance->free_list.load(std::memory_order_relaxed); Block* new_head = blocks[0]; Block* new_tail = blocks[count - 1]; do { new_tail->next.store(old_head, std::memory_order_relaxed); } while (!pool_instance->free_list.compare_exchange_weak(old_head, new_head, std::memory_order_release, std::memory_order_relaxed)); count = 0; } }; - 这里为什么把缓存的block块设置为32, 并且每次取的大小设置为16。
-
继续看下我们的类成员的定义:
- 我们要把ThreadCache 声明为thread_local 类型,这样每个线程都会存在一份缓存
- free_list 为全局缓存,所有空闲的block块都会链接到这个list 里面。
- chunks 分配的chunk由LockFreeStack 来管理,避免内存泄露
- allocate_count 为分配一个block的计数, deallocated_count 为归还一个block的计数。
static inline thread_local ThreadCache local_cache; static inline constexpr size_t BLOCK_PER_CHUNK = N / sizeof(Block); std::atomic<Block*> free_list{nullptr}; LockFreeStack<std::unique_ptr<Chunk>> chunks; std::atomic<size_t> allocate_count{0}; std::atomic<size_t> deallocated_count{0}; -
分配一个新的chunk.
- 先使用make_unique分配一个chunk的大小,其中包含BLOCK_PER_CHUNK的block。
- 获取block的指针。
- 这里我们先把block串联起一个链表,然后使用一次原子操作即可。
- 第一次分配的都是空的,所有把所有的block都放进free_list 里面去。
- 最后把chunk放到LockFreeStack里面管理。
void allocate_new_chunk() { auto chunk = std::make_unique<Chunk>(BLOCK_PER_CHUNK); Block* blocks = chunk->blocks.get(); // 准备链表,只在最后一步进行一次原子操作 auto* first_block = &blocks[0]; for (size_t i = 0; i < chunk->count - 1; ++i) { blocks[i].next.store(&blocks[i+1], std::memory_order_relaxed); } Block* old_head = free_list.load(std::memory_order_relaxed); do { blocks[chunk->count-1].next.store(old_head, std::memory_order_relaxed); } while(!free_list.compare_exchange_weak(old_head, first_block, std::memory_order_release, std::memory_order_relaxed)); //将所有块链接到空闲列表 chunks.push(std::move(chunk)); } -
然后我们再看看怎么把free_list 里面的数据批量取出来放到thread_cache里面去。
- 首先获取这个对象的instance, 如果缓存还有剩余,那么不需要从free_list里面取。
- 否则检查free_list 有没有空闲的块了,如果没有分配一个新的chunk.
- 这里我们直接从free_list 里面取ThreadCache::BATCH_SIZE 大小的block的链表,把获取的块放到chche的数组里面。
// 批量获取块到本地缓存 void fill_local_cache(ThreadCache& cache) { cache.pool_instance = this; // 如果本地缓存还有剩余,则直接返回 if (cache.count > 0) return; // 从全局空闲列表中获取块 int batch_size = ThreadCache::BATCH_SIZE; Block* head = nullptr; Block* tail = nullptr; Block* new_head = nullptr; Block* old_head = free_list.load(std::memory_order_acquire); do { // 如果全局链表为空,分配新的块 if (!old_head) { allocate_new_chunk(); old_head = free_list.load(std::memory_order_acquire); if (!old_head) return; // 如果还是仍然为空,返回 } head = old_head; Block* current = old_head; int count = 0; while (count < batch_size - 1 && current->next.load(std::memory_order_relaxed)) { current = current->next.load(std::memory_order_relaxed); ++count; } tail = current; new_head = tail->next.load(std::memory_order_relaxed); } while(!free_list.compare_exchange_weak(old_head, new_head, std::memory_order_release, std::memory_order_relaxed)); // 将获取到的块存储到本地缓存 Block* current = head; int i = 0; while (current != new_head) { cache.blocks[i++] = current; current = current->next.load(std::memory_order_relaxed); } cache.count = i; }- 分配函数
- allocate 是参数是一个可变参数,允许n个参数原封不动传给T对象。
- 我们首先获取数据从cache里面获取,如果没有,调用fill_local_cache 缓存cache数据。
- 如果本地缓存失败了(一般不会出现,除非没内存了), 从free_list 分配一个block, 如果free_list 也没有了,则分配一个新的chunk。 最后返回指向数据的指针,也就是Block的首地址。
template<typename... Args> T* allocate(Args&&... args) { if (local_cache.count == 0) { fill_local_cache(local_cache); } Block* block = nullptr; // 尝试从本地缓存获取块 if (local_cache.count > 0) { block = local_cache.blocks[--local_cache.count]; } else { // 本地缓存填充失败,直接从全局获取单个块 Block* old_block = free_list.load(std::memory_order_acquire); // 先尝试从空闲列表中获取一个块 while(old_block) { if (free_list.compare_exchange_weak(old_block, old_block->next.load())) { block = old_block; break; } } // 如果空闲列表为空,则分配一个新的块 if (!block) { allocate_new_chunk(); old_block = free_list.load(std::memory_order_acquire); while(old_block) { if (free_list.compare_exchange_weak(old_block, old_block->next.load())) { block = old_block; break; } } } } allocate_count.fetch_add(1); if (block) { // 构造新对象 return new (block->as_object()) T(std::forward<Args>(args)...); } return nullptr; }- 最后看下deallocate的函数
- 释放的时候先会去调用对象的析构函数
- 把数据的指针转为block的指针
- 这里我们有个策略就是如果本地缓存的数量,有可能归还超过总的大小,所以我们会预先检测本地缓存的是否已经大于了容量的80%, 如果已经超过的话,就先把一半的缓存还给free_list 里面,这样确保cache里面有足够的空间。
- 最后再把block 放到cache里面去。
void deallocate(T* ptr) { if (!ptr) return; ptr->~T(); /* Block 结构的第一个成员就是 data 数组 as_object() 方法返回的是 data 数组的起始地址 通过 alignas(T) 确保 Block 的对齐要求满足 T 的需求 因此,指向 T 对象的指针实际上就是指向 Block 结构体中 data 数组的指针,而 data 数组又在 Block 的起始位置,所以可以安全地将 T 指针转回 Block 指针。 内存布局: Block 对象: +----------------------+ | data[sizeof(T)] | <-- 用户获得的 T* 指针指向这里 +----------------------+ | next | +----------------------+ */ Block* block = reinterpret_cast<Block*>(ptr); local_cache.pool_instance = this; // 确定本地缓存容量 const int cache_capacity = static_cast<int>(sizeof(local_cache.blocks) / sizeof(local_cache.blocks[0])); // 如果本地缓存已近容量的80%,预先归还一半 if (local_cache.count >= cache_capacity * 0.8) { int half_count = local_cache.count / 2; // 构建链表 for (int i = 0; i < half_count - 1; ++i) { local_cache.blocks[i]->next.store(local_cache.blocks[i + 1], std::memory_order_relaxed); } // 归还到全局链表 Block* old_head = free_list.load(std::memory_order_relaxed); Block* cache_head = local_cache.blocks[0]; Block* cache_tail = local_cache.blocks[half_count - 1]; do { cache_tail->next.store(old_head, std::memory_order_relaxed); } while (!free_list.compare_exchange_weak(old_head, cache_head, std::memory_order_release, std::memory_order_relaxed)); // 压缩剩余缓存 for (int i = 0; i < local_cache.count - half_count; ++i) { local_cache.blocks[i] = local_cache.blocks[i + half_count]; } local_cache.count -= half_count; } // 现在将新块添加到本地缓存 local_cache.blocks[local_cache.count++] = block; deallocated_count.fetch_add(1, std::memory_order_relaxed); }- 测试结果(和标准的分配器)
- 可以看到比标准的分配器还是快了一点。PS: 后面有时间可以继续优化下。
Standard allocator time: 2450 microseconds Fixed size pool time: 1790 microseconds
源代码: https://github.com/birate-wz/myUtils/tree/master/MemoryPool
MultiSizePool
MultiSizePool 意思是说我们会分配多个不同大小的chunk,来满足不同size的分配的要求。就像下面的图一样, chunk1~chunk5是不同大小size的chunk,每个chunk下面都有一个block链表来存储数据,同样我们会把空闲的block 放到freelist 中去。
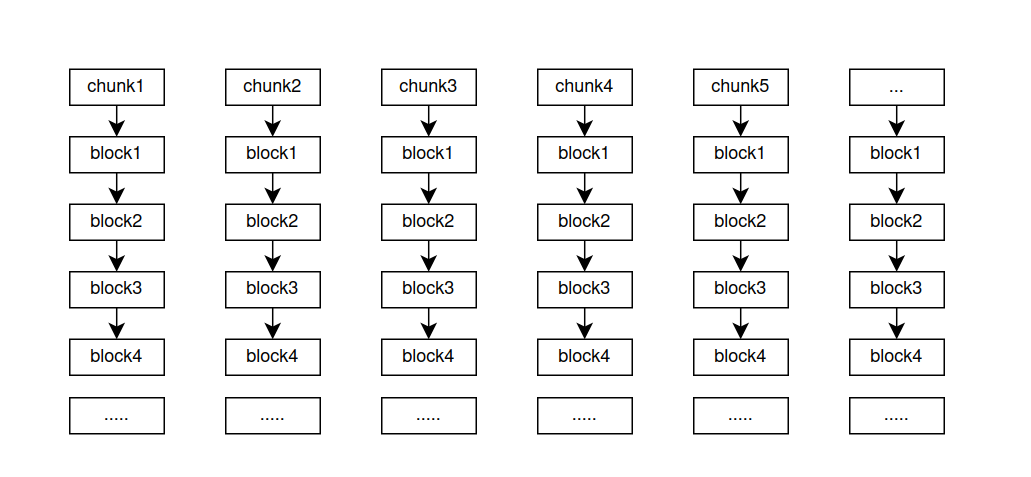
为了增加性能,我们同样也开辟了了线程缓存,每个线程都有一份自己的缓存,每次取的时候都会先从ThreadCache中先取空闲的block,如果没有了我们再从对应大小的chunk中的freelist 来分配。
Chunk的数组
定义了一个chunk的不同size的数组,可以看到size从8 byte到2k byte 大小不等,这些为小对象的size, 对于超过这些size的,我们直接分配对应的大小(大对象)。 这里的每个size都是一个chunk, 每个chunk都存储了若干个block;block 会预先放到freelist 里面。这里会记录一个block data的大小(block_size), 还有总的大小(block 结构体 + data size);我们会使用 ALIGNMENT 对齐,这里我们是根据C++标准定义’std::max_align_t’,我们这里是16. block_count 的大小我们就可以计算出来啦,CHUNK_SIZE 我们预定义为64k。
我们再看下FreeBlock结构体的定义,定义了一个指向next的指针和size的大小。这里会把存储的数据区放到结构体的后面。
内存结构: struct FreeBlock + data
所以这里有两个函数用于从结构体的首地址指向data 数据区的指针; 和从数据区转到指向结构体地址的指针。
static constexpr std::array<size_t, 16> SIZE_CALSSES = { //max 2k
8, 16, 24, 32, 48, 64, 96, 128, 192, 256, 384, 512, 768, 1024, 1536, 2048
};
struct ChunkClass {
std::atomic<FreeBlock*> free_list;
std::atomic<size_t> allocated_count;
std::atomic<size_t> deallocated_count;
size_t block_size; // 每个block data size
size_t total_block_size; // 一个block + data的大小
size_t block_count; // 每个chunk的block数量
ChunkClass() = default;
explicit ChunkClass(size_t size):
free_list(nullptr),
block_size(size),
total_block_size(align_of(sizeof(FreeBlock) + size, ALIGNMENT)),
block_count(CHUNK_SIZE / total_block_size)
{}
};
// 内存结构: FreeBlock + data
struct FreeBlock {
size_t size;
std::atomic<FreeBlock*> next;
FreeBlock(size_t s):size(s), next(nullptr) {}
void* data() { // 指向data 数据
return reinterpret_cast<std::byte*>(this) + sizeof(FreeBlock);
}
static FreeBlock* from_data(void* ptr) { // 从data 数据获取FreeBlock指针
return reinterpret_cast<FreeBlock*>(reinterpret_cast<std::byte*>(ptr) - sizeof(FreeBlock));
}
};
MultiSizeThreadCache 是一个高效的线程本地缓存实现,它在无锁内存池中扮演着至关重要的角色。这个结构通过减少线程间的竞争,显著提升内存分配和释放的性能。
- 线程局部存储: 使用
thread_local关键字确保每个线程拥有自己独立的缓存实例 - 分层缓存结构: 为每种内存块大小(SIZE_CLASSES)维护独立的缓存队列
- 高效访问: 通过数组实现O(1)时间复杂度的块访问
这里我们定义了一个ClassCache来缓存freelist的空闲block,每个chunk size都有一个大小32的block的缓存, count是记录还剩多少的缓存数量。
内存回收机制
当线程终止时,析构函数负责将缓存的所有内存块归还到全局池:
这个过程包含三个关键步骤:
- 链表构建: 将离散的块连接成一个链表,准备批量归还
- 原子交换: 使用
compare_exchange_weak确保线程安全地将链表插入全局链表头部 - 计数重置: 归还完成后将缓存计数归零
通过这种线程本地缓存设计,内存池实现了高吞吐量和低延迟的内存分配,特别适合高并发环境下的性能关键型应用。
struct MultiSizeThreadCache {
struct ClassCache {
FreeBlock* blocks[32]; // 每个大小类缓存块
int count; // 当前缓存的数量
};
ClassCache caches[SIZE_CALSSES.size()];
LockFreeMultiSizePool* pool_ptr; // 指向全局内存池
~MultiSizeThreadCache() {
if (!pool_ptr) return;
// 遍历所有大小类
for (size_t index = 0; index < SIZE_CALSSES.size(); ++index) {
auto& class_cache = caches[index];
if (class_cache.count == 0) continue;
// 将块连接成链表
for (int i = 0; i < class_cache.count - 1; ++i) {
class_cache.blocks[i]->next.store(class_cache.blocks[i + 1], std::memory_order_relaxed);
}
auto& chunk_class = pool_ptr->chunk_classes[index];
FreeBlock* old_head = chunk_class.free_list.load(std::memory_order_relaxed);
FreeBlock* cache_head = class_cache.blocks[0];
FreeBlock* cache_tail = class_cache.blocks[class_cache.count - 1];
// 归还到全局链表
do {
cache_tail->next.store(old_head, std::memory_order_relaxed);
} while (!chunk_class.free_list.compare_exchange_weak(old_head, cache_head,
std::memory_order_release,
std::memory_order_relaxed));
class_cache.count = 0;
}
}
};
std::array<ChunkClass, SIZE_CALSSES.size()> chunk_classes;
LockFreeStack<std::unique_ptr<std::byte[]>> allocated_chunks;
static constexpr size_t ALIGNMENT = alignof(std::max_align_t);
static constexpr size_t CHUNK_SIZE = 64 * 1024; // 64k
static inline thread_local MultiSizeThreadCache thread_cache;